Kubeflow
Spark Operator
Define your Spark job in a single custom resource and run it on Kubernetes like any other workload.
kubectl apply. The operator runs spark-submit for you.What is Kubeflow Spark Operator?
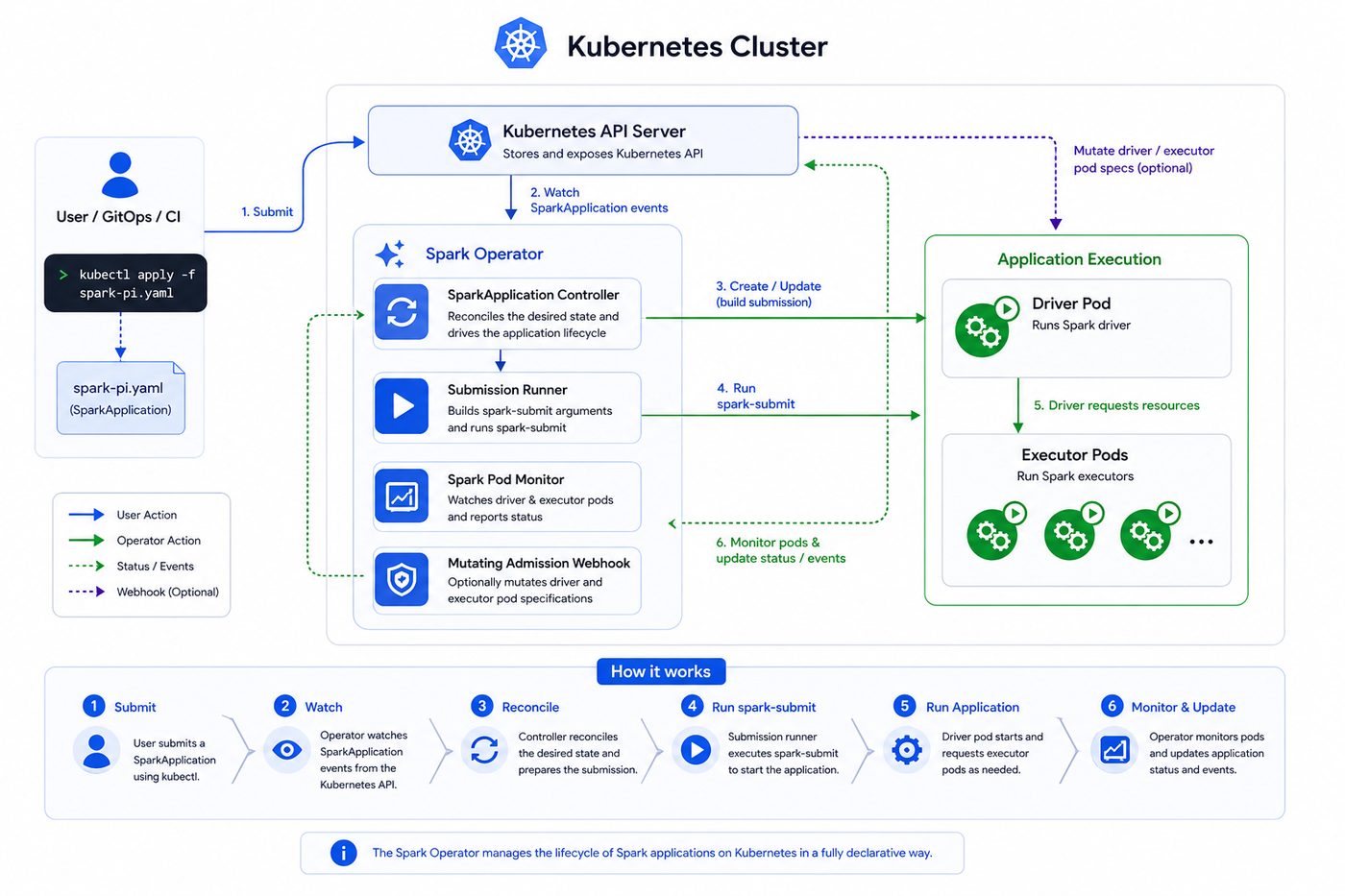
The Kubernetes Operator for Apache Spark lets you run Spark applications as naturally as any other Kubernetes workload. Describe a job in a YAML SparkApplication and apply it to your cluster. The operator does the rest, running spark-submit, tracking the driver and executor pods, restarting failed runs, scheduling recurring jobs, and exporting metrics. You never touch the Spark submission process yourself.
Kubeflow Spark Operator is a core component of Kubeflow, the open-source foundation of tools for building AI platforms on Kubernetes.
Why Spark Operator?
Declarative Applications
Define Spark applications with the SparkApplication custom resource and manage them through the Kubernetes API. No manual spark-submit required.
Native Cron Scheduling
Run Spark jobs on a schedule with ScheduledSparkApplication, including configurable concurrency policies and history limits.
Pod Customization
Go beyond what Spark offers natively using the mutating admission webhook. Mount ConfigMaps and volumes, and set affinity, tolerations, and more on driver and executor pods.
Metrics & Monitoring
Collect and export application-level and driver/executor metrics to Prometheus, with optional JMX exporter integration for deep observability.
Batch Scheduling
Integrate with Volcano, Apache YuniKorn, and the Kubernetes scheduler plugins for gang scheduling and resource-aware placement of Spark workloads.
Production Ready
A core part of the Kubeflow ecosystem, backed by the CNCF community. It restarts applications automatically, retries with backoff, and resubmits updated specs.
Core Capabilities
How It Works
You submit a SparkApplication with kubectl, and the operator reconciles it. It builds the submission, runs spark-submit, and watches the driver and executor pods until the job finishes.
See It in Action
Best practices for running Apache Spark on Kubernetes with the Kubeflow Spark Operator, presented at CNCF KubeCon NA 2024.
Documentation
Everything you need, from your first Spark job to running in production and contributing back.
Learn what the Spark Operator is, its architecture, and how it manages the lifecycle of Spark applications
Getting StartedInstall the operator with Helm and run your first SparkApplication in minutes
User GuideWrite, configure, schedule, monitor, and operate SparkApplications in depth
PerformanceBenchmarking results and tuning guidance for high-throughput Spark workloads
ReferenceThe v1beta2 API definition for SparkApplication and ScheduledSparkApplication
Set up your development environment and contribute to the Spark Operator project
Submit a Spark Job in One File
# spark-pi.yaml
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: spark:4.0.1
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: local:///opt/spark/examples/jars/spark-examples.jar
sparkVersion: "4.0.1"
driver:
cores: 1
memory: "512m"
executor:
instances: 2
cores: 1
memory: "512m"Run kubectl apply -f spark-pi.yaml. The operator runs spark-submit and tracks the job for you. See the full quickstart →
Join the Community
We are an open and welcoming community of developers, data engineers, and organizations. The project is part of the Cloud Native Computing Foundation.